library(tidyverse) # ggplot, lubridate, dplyr, stringr, readr...
library(tidytext)
library(praise)
library(paletteer)
library(ggforce)
library(networkD3)
library(plotly)Holiday Movies
The Data
The data this week comes from the Internet Movie Database. We don’t have an article using exactly this dataset, but you might get inspiration from this Christmas Movies blog post by Milán Janosov at Central European University.
movies <- read_csv("holiday_movies.csv")
genres <- read_csv("holiday_movie_genres.csv")How has genre changed over time?
movies |>
filter(runtime_minutes >= 20) |>
inner_join(genres, by = "tconst") |>
group_by(genres.y) |>
mutate(count = n()) |>
filter(count > 100) |>
group_by(year, genres.y) |>
summarize(count = n())|>
ggplot(aes(x = year, y = count, fill = genres.y, label = genres.y)) +
geom_area() +
ggthemes::scale_fill_colorblind() +
scale_x_continuous(breaks = seq(1920, 2020, 10)) +
theme(panel.grid.minor.x = element_blank()) +
labs(x = "", y = "",
title = "Number of holiday films in each genre.",
fill = "")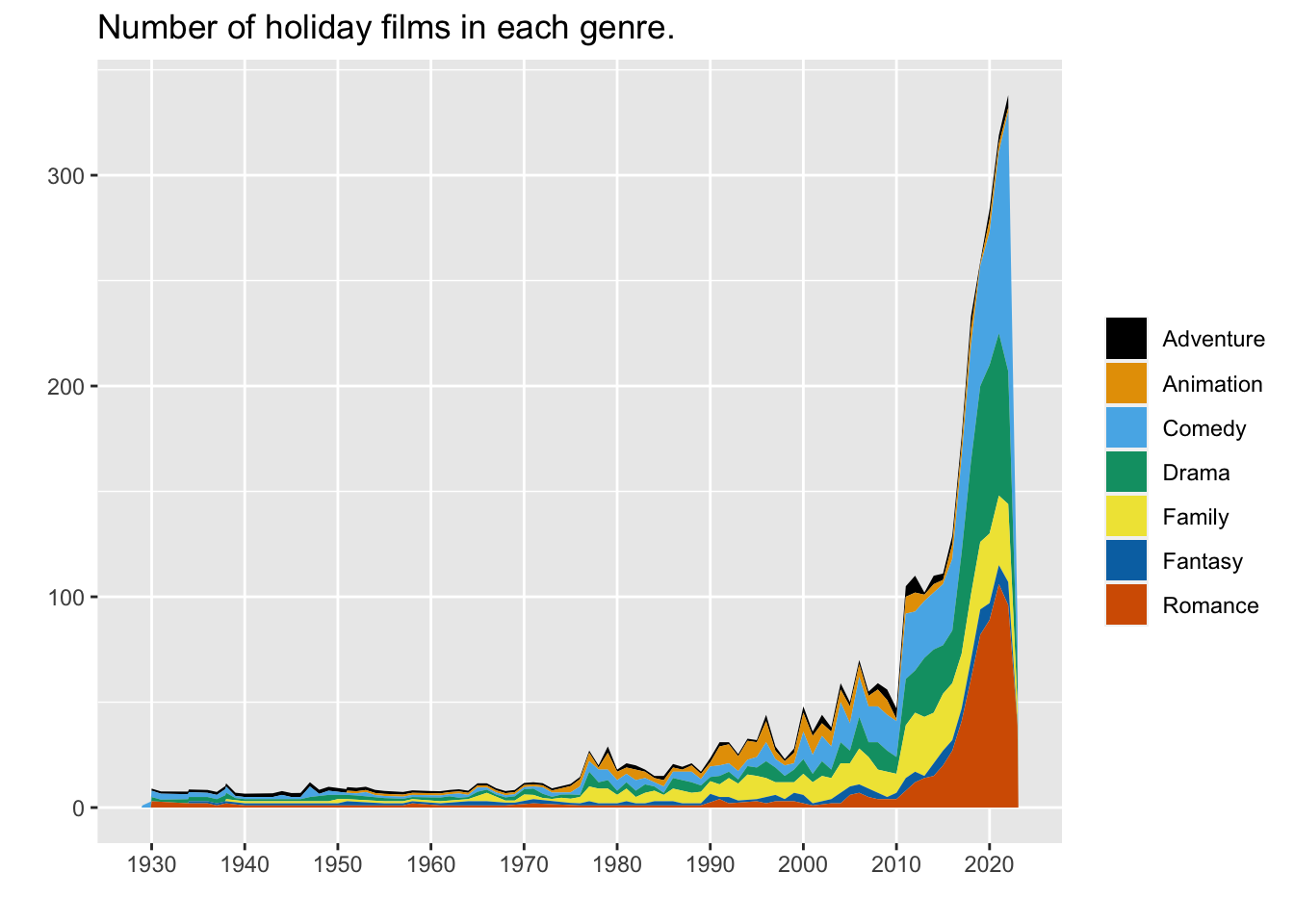
Common holday words and phrases
movies |>
mutate(row = row_number()) |>
filter(!is.na(primary_title)) |>
unnest_tokens(title_words, primary_title, token = "ngrams", n=1) |>
anti_join(stop_words, by = c("title_words" = "word")) |>
group_by(row) |>
summarize(title = paste0(title_words, collapse = ' ')) |>
unnest_tokens(bigrams, title, token = "ngrams", n = 2) |>
count(bigrams, sort = TRUE)# A tibble: 2,585 × 2
bigrams n
<chr> <int>
1 <NA> 135
2 christmas carol 89
3 home christmas 32
4 christmas tree 30
5 merry christmas 30
6 christmas story 26
7 christmas eve 18
8 christmas miracle 16
9 christmas special 15
10 family christmas 15
# ℹ 2,575 more rowslibrary(ggupset)
genres |>
group_by(tconst) |>
summarize(genre_list = list(genres)) |>
ggplot(aes(x = genre_list)) +
geom_bar() +
scale_x_upset(n_intersections = 20) +
labs(x = "", y = "", title = "Number of holidy movies in each (combination of) genre(s).")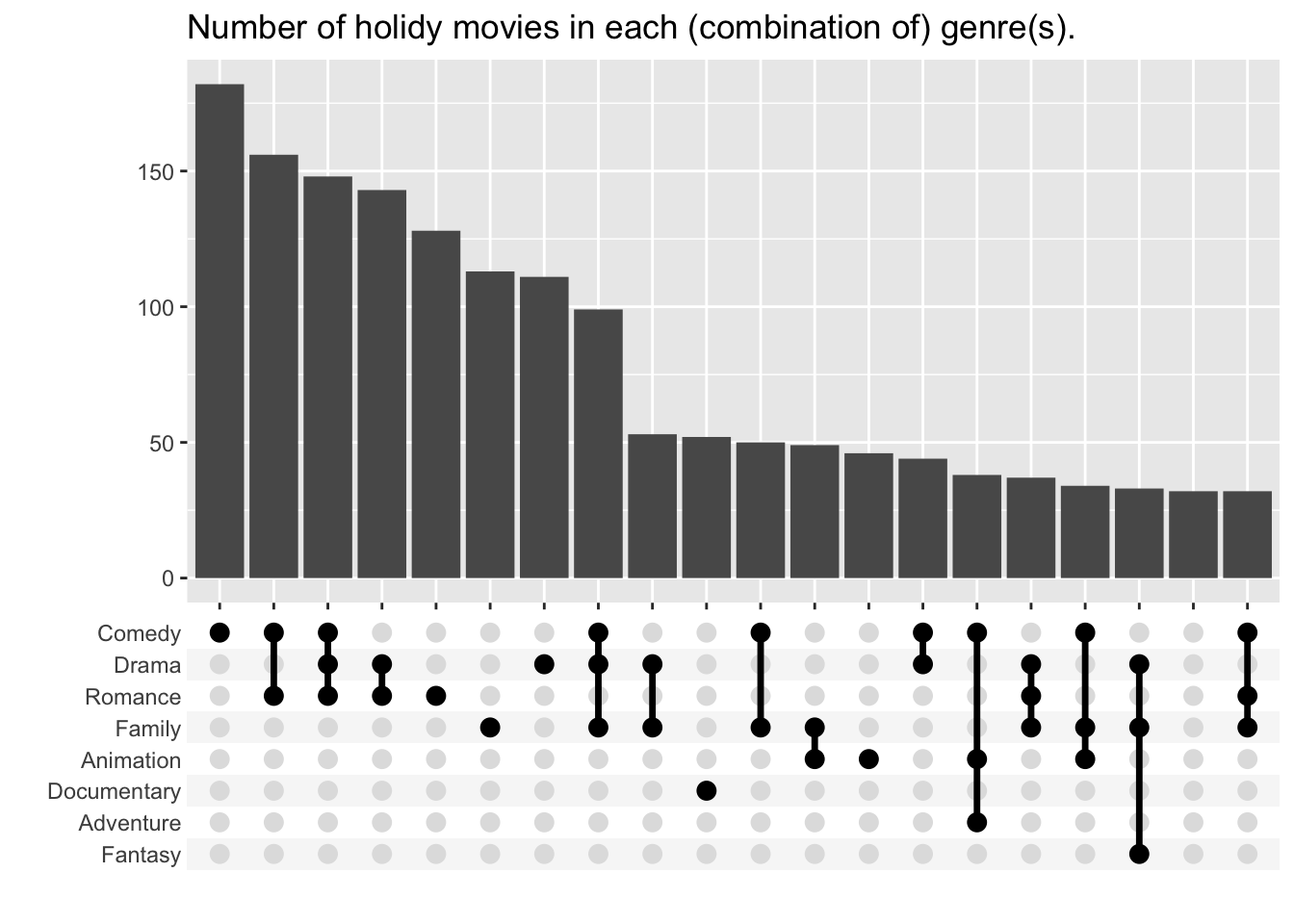
praise()[1] "You are fabulous!"