library(tidyverse)
library(tidytext)
library(praise)African Language Sentiments
The Data
The data this week comes from AfriSenti: Sentiment Analysis dataset for 14 African languages via @shmuhammad2004 (the corresponding author on the associated paper, and an active member of the R4DS Online Learning Community Slack).
afrisenti <- read_csv("afrisenti.csv")
ibo <- afrisenti %>%
filter(language_iso_code == "ibo")Unnesting words and whatnot
ibo_top <- ibo %>%
unnest_tokens(word, tweet, token = "ngrams", n = 2) %>%
group_by(word) %>%
filter(!(word %in% c("https t.co"))) %>%
filter(!str_detect(word, "user")) %>%
summarize(freq = n(), pos = mean(label == "positive"),
neg = mean(label == "negative"),
neut = mean(label == "neutral")) %>%
arrange(desc(freq)) %>%
head(10) %>%
pivot_longer(pos:neut, names_to = "sentiment", values_to = "proportion") %>%
mutate(english = case_when(
word == "nke a" ~ "this one",
word == "ndi igbo" ~ "Igbo people",
word == "na eme" ~ "and do",
word == "ka m" ~ "like me",
word == "ike gwuru" ~ "tired",
word == "happy birthday" ~ "happy birthday",
word == "gozie gi" ~ "bless you",
word == "gi na" ~ "you and",
word == "chukwu gozie" ~ "God bless",
word == "a na" ~ "a"
))ibo_top %>%
ggplot(aes(x = reorder(word, desc(freq)), y = proportion, width = freq, fill = sentiment)) +
geom_bar(stat = "identity", position = "fill", color = "grey") +
geom_text(y = 0.12, aes(x = reorder(word, desc(freq)), label = english)) + #,
# hjust = 0, vjust = .025, angle = 90, stat = "unique") +
coord_flip() +
facet_grid(reorder(word, desc(freq)) ~ 1, scales = "free_x", space = "free_x") +
theme_void() +
xlab("") +
scale_fill_brewer(palette = 4) +
labs(title = "Most common 2-grams in Ibo tweets",
subtitle = "width proportional to # of tweets\ncolored by proportion of tweets with each sentiment",
caption = "TidyTuesday AfriSenti\n GitHub: @hardin47\nData from @shmuhammad2004")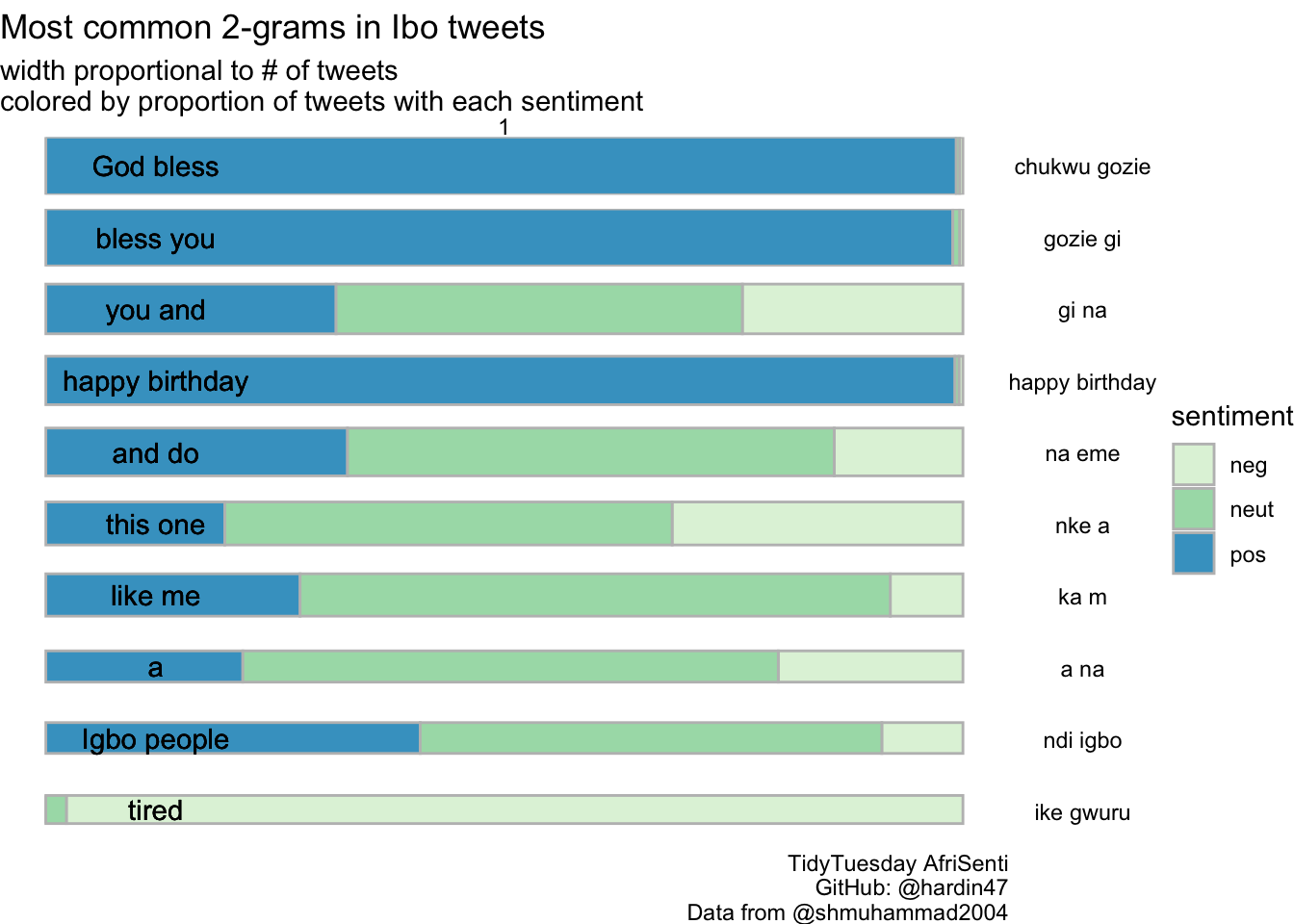
praise()[1] "You are world-class!"